Di seguito gli interventi pubblicati in questa sezione, in ordine cronologico.
PREMESSA: questo articolo è basato su un test da me condotto e mi piacerebbe avere verifica dai lettori di questo blog.
Tempo fa ho notato una stranezza, non avendo cavato ancora una soluzione, ho pensato di sottoporla al pubblico del mio blog, sottolineo che è basato su una sola prova, sulla quale non ho ancora una spiegazione, che potrei non avere per mia "ignoranza", quindi vorrei altre opinioni e/o sperimentazioni.
Detto questo passo a descrivere l'esperimento:
da Linux (senza montare nè in lettura nè in scrittura)
1) attacco una pendrive da 128Mb formattata in NTFS
2) Faccio l'immagine dd e la chiamo pen1.dd
3) faccio l'md5sum
da Windows XP:
4) attacco il pendrive da 128Mb
5) la stacco con RIMOZIONE SICURA
da Linux
6) faccio immagine dd e la chiamo pen2.dd
7) faccio md5sum
8) confronto i due md5 e noto che SONO DIVERSI.
La pendrive è vuota, la pendrive NON è stata sfogliata, la pendrive è stata solo attaccata a Windows e staccata con rimozione sicura.
A questo punto prendo le due immagini e le confronto con un programma (per windows) che si chiama HexCMP2
Cerco le differenze e tutte cadono nel cluster del file $LogFile, che è il journal di NTFS.
Per esempio l'ultima differenza è nell'offset in decimale: 40203262
9) faccio mmls pen1.dd ricavo l'offset di partenza della partizione che è 32
10) fsstat -f ntfs -o 32 pen1.dd e ricavo la dimensione del cluster che è
512
11) divido 40203262 per 512=78521 che è l'offset in settori
12) ifind -f ntfs -o 32 -d 78521 pen2.dd
mi tira fuori: 2-128-1
ffind -f ntfs -o 32 pen2.dd 2-128-1
mi tira fuori
//$LogFile
13) istat -f ntfs -o 32 pen1.dd 2-128-1 | less
istat -f ntfs -o 32 pen2.dd 2-128-1 | less
e noto che la data e l'ora sono identici, quindi il file $Logfile viene modificato, ma i suoi metadati no! Why?
RIFACCIO il procedimento SENZA la RIMOZIONE SICURA, ma staccando brutalmente la chiavetta ed ottengo gli stessi risultati, solo che l'ultima modifica è all'offset decimale:
40174590
diviso 512 =78465
Quindi meno modifiche con la rimozione bruta.
Per concludere ho notato che quando si fa la RIMOZIONE SICURA, sul display del pendrive, appare la scritta WRITE (è un pendrive con display, lettore MP3), quindi quella procedura scrive qualcosa...
PROBLEMA:
Se un CTU maldestro, attacca un disco NTFS ad una stazione Windows, senza il Write Blocker, altera il disco originale, però non v'è traccia di questa alterazione, in termini di timeline....l'hash code che calcolerà sarà quello che verrà generato dall'hard disk già alterato, quindi copia ed originale avranno lo stesso hash code.
In un secondo tempo, un CTP riprende il disco originale, lo attacca con Write Blocker, fa l'immagine e l'hash coinciderà con quello del CTU, dato che il CTP non ha alterato alcunchè...
In soldoni, il CTU ha modificato l'originale, ma non c'è traccia di data ed ora successiva al giorno del sequestro, quindi non v'è modo di dimostrare che ha attaccato l'hd originale ad un sistema sprotetto da
scrittura.
Il problema è chiaramente più teorico che pratico, ci son cose peggiori in giro ;)
Per concludere, le stesse prove fatte con FATx danno MD5 identici, forse perchè FATx non è Journaled, mentre NTFS sì...e $Logfile è il journal di ntfs.
Ogni opinione, smentita, conferma è gradita !!! 
ARTICOLO SU ISSA JOURNAL
Nanni Bassetti
Con la diffusione dei netbook e dei sistemi che bootano da porta USB, ho proposto a Giancarlo Giustini, il project manager di CAINE (la Linux Live distro per la computer forensics), di realizzarne una versione bootabile da usb e lui mi ha dato "luce verde".
L'abbiamo chiamata NBCAINE (NetBook Caine) ed ora passo ad una breve descrizione:
NBCAINE è un'immagine raw (dd, bitstream, ecc.), di un pendrive da 1GB, contenente la versione LiveUsb di Caine e la parte Windows side rappresentata da Wintaylor, inoltre si sono aggiunti altri tools per l'analisi live su sistemi windows.
In questo modo si ha in tasca un sistema veloce e pronto per il futuro dei nostri PC, che permette di compiere le stesse operazioni di un LiveCd Linux ed anche di fare un'analisi live su un sistema Windows based, grazie a Wintaylor, che annovera tool utilissimi come, per esempio, WFT.
Come si usa:
Una volta scaricata l'immagine si deve aprire una terminal window e:
1) gzip -d nbcaine.dd.gz (Limmagine va prima scompattata con gzip)
2) sudo dd if=nbcaine.dd of=/dev/sdX (dove /dev/sdX è la vostra pendrive vergine)
Fatto questo potete aggiungere il plugin Flash, manualmente, andando nella directory
/casper/flash.dir/usr/lib/xulrunner-addons/plugins/
della vostra neonata pendrive ed aggiungere il file libflashplayer.so presente nella versione .tar.gz del plugin scaricabile da QUI.
E per chi ha pendrive più grandi di 1GB? Non c'è problema funziona ugualmente.... 
DOWNLOAD NBCAINE
Ormai il Web 2.0 impazza, siamo tutti più o meno protagonisti in varie piazze virtuali, ci si innamora, si litiga, si stringono amicizie, si fanno guerre ideologiche, ci si critica, insomma tutto il bene e tutto il male che l'uomo può esprimere.
Diffamazione, stalking, violazione del copyright, ecc. ecc. sono tra i fatti, che posson accadere sul web, ma tecnicamente e giuridicamente diventa difficile "cristallizare" una pagina web e farne una copia conforme, perchè essa è spesso dinamica, essa spesso cambia, il proprietario ne altera il contenuto appena sente puzza di bruciato e tante altre motivazioni, note a chi si occupa di computer forensics.
Ecco che Gianni Amato e Davide Baglieri, con il testing ed i suggerimenti di tanti membri di CFI (Computer Forensics Italy), compreso lo scrivente, hanno sviluppato HashBot http://www.hashbot.com/.
Curiosi di saperne di più? Lascio l'approfondimento ad uno dei suoi creatori:
http://www.gianniamato.it/2009/04/hashbotcom-congela-un-documento-web-e.html
Buona lettura ;)
Raw2FS, acronimo che serve ad indicare lo scopo di questo mio nuovo bash script per Linux, ossia ricondurre i nomi dei file estratti con tool come Foremost, al nome presente nel file system, con tutto il suo percorso.
Sappiamo che Foremost, come altri carver, salvano i file nominandoli col numero di settore (da 512 bytes), di partenza, in cui questi si trovano, quindi mi serviva uno strumento per risalire all'eventuale nome presente nel file system.
Se il file "carvato" non ha corrispondenza con un i-node allora il tool salva l'output hex/ascii di un settore/cluster/block in un file di testo.
Tutto è riassunto in un report in HTML.
Ma visto che ero in argomento, perchè non implementare anche una ricerca per stringhe? Raw2Fs permette di cercare più keywords oppure di caricare un file di testo, generato dal "grepping" e riportare tutti i file nel file system che contengono quelle keywords, se invece la keyword è contenuta nello slack space, allora viene salvato l'output hex/ascii di un settore/cluster/block.
Il motore di tutto è questo:
se ho un file nominato 00001234.doc (carving), quel numero "1234" rappresenta il settore in cui il file è stato trovato dal carver, quindi lo si moltiplica per 512 (dimensione minima del settore) e si ottiene l'offset in byes del file, che chiamremo $offcarv.
Poi il tool cerca a quale partizione appartiene il file, trova l'inizio della partizione/spazio non allocato e moltiplica lo starting sector x la dimensione del settore/cluster/blocco (es. 1024), che chiameremo $ss, per ottenere l'offset in bytes della partizione, che chiameremo $offbytepart. (ricodiamo che per fat -> settore, ntfs -> cluster, ext2/3 -> blocco).
Ed ecco la formuletta:
($offcarv - $offbytepart) / $ss
Ossia l'offset del file carvato - l'offset di inizio partizione diviso la grandezza del settore/cluster/blocco usato in quella partizione da quel file system.
Poi tramite i tools dello Sleuthkit, Raw2Fs fa tutto il resto.... :)
Per le keywords stesso discorso, solo che nel file derivante dalla ricerca con strings e grep, si trovano già gli offset in bytes delle stringhe, quindi non c'è bisogno di moltiplicare per 512.
Dopo quest'ennesima "fatica", ho pensato di lanciare il sito:
http://scripts4cf.sf.net
contenente alcuni scripts utili, ad oggi realizzati da me e da Denis Frati, ma aperto ad ospitare anche scripts fatti da altri, insomma una vera e propria piccola biblioteca di tools costruiti dagli "investigatori digitali", man mano che si trovano a dover affrontare e risolvere i problemi che incontrano durante le loro indagini e/o esercizi.
Spero di aver fatto cosa utile... ;)
Denis Frati ed il sottoscritto hanno appena pubblicato l'ultima release di Selective File Dumper, SFDumper per gli amici ;)
Quali sono le novità?
- Adesso il software lavora su device e su immagini di tipo raw/ewf/aff e splittate, una grande comodità per tutti.
- L'output è più ordinato e pulito.
- Non ci sono più errori di output dovuti ai file orfani.
- Può essere avviato in modalità "linea di comando" oppure in modalità interattiva (alla vecchia maniera di SFDumper).
- C'è la possibilità di operare al meglio su immagini di device con file system hfs/hfs+, utilizzando le feature messe a disposizione dagli Snapshots di SleuthKit.
- Ci sono i numeretti che indicano l'avanzamento del lavoro, mentre il software è in esecuzione.
Insomma sono novità importanti, che hanno eliminato i problemi di recupero su alcuni file ed hanno reso lo strumento molto più flessibile e potente.
Sito del tool http://sfdumper.sourceforge.net .
Muchas gratias
Abbiamo fatto uscire la SFDumper 2.1, finalmente adesso tutti i problemini sui nomi file e il filtraggio per estensione sono stati risolti. Try it: http://sfdumper.sourceforge.net/Thanks
Se si formatta un disco o una pendrive usb, per esempio NTFS, sia con formattazione lenta sia con quella veloce, viene ricreata la MFT (Master File Table), giusto?
I file non vengono cancellati, spariscono alla vista, solo perchè non v'è più un indice, una MFT, che dice al file system dove sono e come si chiamano, ergo usiamo il carving ,(tecnica che non tiene conto del file system), per recuperarli...peccato che si perdono i nomi ed i metadati (data ed ora,e cc.)...giusto?
Non c'è più modo per riavere i nomi dei file, perchè non c'è più MFT che li conserva, essa è stata sovrascritta dalla nuova MFT e tutte le MFT si allocano all'inizio del disco.
Ma come fa RECUVA o R-Studio a recuperare i nomi dei file, ora e date???
L'ho provato su una chiavetta formattata 2 volte, una veloce ed una lenta e poi anche formattando da Linux e comunque riesco a ritrovare alcuni file con il loro nome:
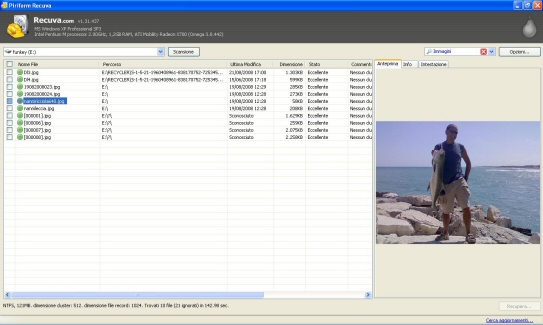
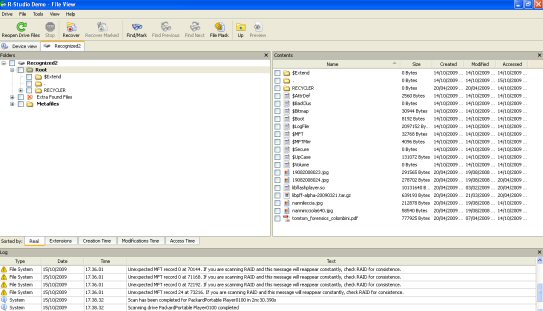
Ho provato con R-Studio ed anche lui ci riesce...solo che ho notato che recupera alcuni metafile della MFT tipo $MFTMirr, $MFTReconstructed, $AttrDef, $Bitmap, $Upcase, $MFT, $Logfile, $Boot che non sono a "0".
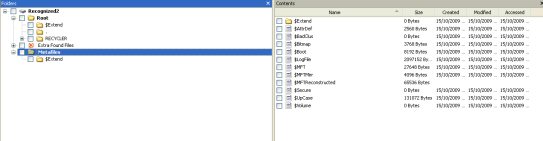
Quindi la spiegazione è che in qualche maniera questi metafile non sono stati sovrascritti con quelli nuovi del nuovo filesystem NTFS quando si formatta...però è strano!
Allora ho voluto provare a "scavare", per capire meglio ed ecco cosa ho ricavato:
strings -a -t d -e l /dev/sdb (ricavo le stringhe contenute nel dispositivo)
...
...
42281714 Dl3.jpg
42282738 Dl4.jpg
42282858 15062008013.jpg
42283762 190820~2.JPGjpg0
42283882 19082008023.jpg
42284786 190820~3.JPGjpg0
42284906 19082008024.jpg
42285810 NANNIR~1.JPGa640
42285930 nanniricciola640.jpg
42286834 NANNIL~1.JPGjpg0
42286954 nannileccia.jpg
...
etc.
Guardo con l'editor esadecimale l'offset in byte 42286954 corrispondente a quello riferito alla stringa: nannileccia.jpg
xxd -s 42286954 -l 512 /dev/sdb
2853f6a: 6e00 6100 6e00 6e00 6900 6c00 6500 6300 n.a.n.n.i.l.e.c.
2853f7a: 6300 6900 6100 2e00 6a00 7000 6700 8000 c.i.a...j.p.g...
2853f8a: 0000 4800 0000 0100 0000 0000 0400 0000 ..H.............
2853f9a: 0000 0000 0000 9f01 0000 0000 0000 4000 ..............@.
2853faa: 0000 0000 0000 0040 0300 0000 0000 8e3f .......@.......?
2853fba: 0300 0000 0000 8e3f 0300 0000 0000 22a0 .......?......".
2853fca: 0165 2800 0100 ffff ffff 8279 4711 0000 ..........e(........yG...
2853fda: 0000 0000 0000 0000 0000 0000 0000 0000 ................
2853fea: 0000 0000 0000 0000 0000 0000 0000 0000 ................
2853ffa: 0000 0000 0b00 0000 0000 0000 0000 0000 ................
285400a: 0000 0000 0000 0000 0000 0000 0000 0000................
Provo a cerca se corrisponde ad un i-node (prova idiota lo so! ma visto che ci siamo )
(42286954 - 0)/512 = 82591 (dato che la partizione inizia dal settore 0 ed il cluster size è di 512 bytes)
ifind -f ntfs -o 0 -d 82591 /dev/sdb
Inode not found
Quindi i nomi file ci sono sulla pendrive, ma non sono contenuti in metafile allocati (giustamente dico io), ma i programmi come Recuva, Get Data Back o R-Studio riescono a riassociare questi nomi file buttati nello spazio del disco formattato con i file presenti e quindi ricostruire l'associazione file - metadato.
Come facciano...bho?
Con Autopsy chiaramente non risultano file cancellati e con una ricerca per DATA UNIT, inserendo il valore 82591, si ottiene la visualizzazione grezza di quel cluster, contenente la stringa "nannileccia.jpg".
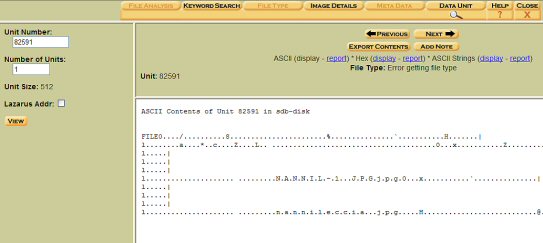
Bhè spero sia argomento interessante ;)
Attendo Vs. suggerimenti
18/10/2009 CONTRIBUTO DI Evgueni Tchijevski
Prova:
-formattato la chiavetta con ntfs :mft entry 1024 byte e cluster da 1024 byte
-aggiunto alcune foto sulla chiavetta
-formattato di nuovo la chiavetta in ntfs
- aggiungo nel file conf di foremost la seguente riga
mft y 1024 FILE0
(in effetti sarebbe stato più corretto aggiungere anche FILE*)
1024 perchè mi serve tutta l'entry mft e la sua dimensione come detto è 1024
faccio il carving sulla chiavetta.
ottengo un sacco di entry mft ed alcune immagini. per brevità riporto quelli che sono considerati nel caso specifico.
(dal file audit.txt)
80: 01302442.mft 1024 B 666850304
.....
116: 01854266.jpg 469 KB 949384192
.....
apro l'entry mft con xxd
soundwave@mrblack:~/lavoro/forense/foremost/foremost-1.5.6/output/mft$ xxd 01302442.mft
0000000: 4649 4c45 3000 0300 7283 4000 0000 0000 FILE0...r.@.....
0000010: 0100 0100 3800 0100 5801 0000 0004 0000 ....8...X.......
0000020: 0000 0000 0000 0000 0300 0000 4000 0000 ............@...
0000030: 0200 0000 0000 0000 1000 0000 6000 0000 ............`...
0000040: 0000 0000 0000 0000 4800 0000 1800 0000 ........H.......
0000050: 40fb dd12 9450 ca01 d0cc 1679 4544 ca01 @....P.....yED..
0000060: 40f4 f312 9450 ca01 40fb dd12 9450 ca01 @....P..@....P..
0000070: 2000 0000 0000 0000 0000 0000 0000 0000 ...............
0000080: 0000 0000 0601 0000 0000 0000 0000 0000 ................
0000090: 0000 0000 0000 0000 3000 0000 7000 0000 ........0...p...
00000a0: 0000 0000 0000 0200 5800 0000 1800 0100 ........X.......
00000b0: 2300 0000 0000 0100 40fb dd12 9450 ca01 #.......@....P..
00000c0: 40fb dd12 9450 ca01 40fb dd12 9450 ca01 @....P..@....P..
00000d0: 40fb dd12 9450 ca01 0058 0700 0000 0000 @....P...X......
00000e0: 0000 0000 0000 0000 2000 0000 0000 0000 ........ .......
00000f0: 0b03 5900 6f00 6b00 6f00 6100 6d00 6900 ..Y.o.k.o.a.m.i.
0000100: 2e00 6a00 7000 6700 8000 0000 4800 0000 ..j.p.g.....H...
0000110: 0100 0000 0000 0100 0000 0000 0000 0000 ................
0000120: d501 0000 0000 0000 4000 0000 0000 0000 ........@.......
0000130: 0058 0700 0000 0000 f457 0700 0000 0000 .X.......W......
0000140: f457 0700 0000 0000 32d6 019d 250e 0000 .W......2...%...
0000150: ffff ffff 8279 4711 0000 0000 0000 0000 .....yG.........
0000160: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000170: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000180: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000190: 0000 0000 0000 0000 0000 0000 0000 0000 ................
ora facendo parsing della entry si ottengono le seguenti info:
strandard information attribute (è riferito alla entry mft)
file creation ( 40fb dd12 9450 ca01) lun, 19 ottobre 2009 08.13.43 UTC
file alteration ( d0cc 1679 4544 ca01) sab, 03 ottobre 2009 16.20.50 UTC
mft alteration ( 40fb dd12 9450 ca01) lun, 19 ottobre 2009 08.13.43 UTC
file read ( 40fb dd12 9450 ca01) lun, 19 ottobre 2009 08.13.43 UTC
file attribute:
file creation lun, 19 ottobre 2009 08.13.43 UTC
file alteration lun, 19 ottobre 2009 08.13.43 UTC
file read lun, 19 ottobre 2009 08.13.43 UTC
un po' di info sulle policy del file Security ID, permission etc...
File allocation size: 0058 0700 ->481280 byte
Filename- >Yokoami.jpg
L'attribute $Data non è residente all'interno dell'$MFT
quindi i dati sono in cluster puntati dalle info contenute:
cioè: number of cluster d6 01 -> 01d6 -> 470 (verifica- >470* 1024 =481280 byte stessa dimensione degli attributi elencati presedentemente)
offset del primo cluster: 9d250e (0e259d- > 927133*1024= 949384192 -guarda caso l'offset del file 01854266.jpg)
quindi 949384192/512- >1854266 (numero del settore).
Quindi ricapitolando. Si possono ottenere le info da una entry mft non più presente nella tabella MFT.
Ora sta a capire il perchè queste info stanno in giro sul disco.
Da quello che ho capito, potrebbe dipendere da allocazioni non residenti di entry mft, da entry presenti all'interno di $LogFile. altre opzioni?
Appena ho un attimo di tempo, cerco di automatizzare il parsing con uno script (se qualcuno ha voglia e tempo per aiutarmi, benvenga :)
my 2cents :)
Evgueni
------------------------------------
CONTRIBUTO DI NANNI BASSETTI 19/10/2009:
Se faccio una ricerca simile:
strings -t d /dev/sdb | grep -i file0
....
....
72192 FILE0
73216 FILE0
74240 FILE0
75264 FILE0
40154592 FILE0
40155152 FILE0
40158688 FILE0
40159248 FILE0
40162784 FILE0
...
...
(i puntini stanno per eccetera eccetera)
Insomma sembra esserci un "buco" tra i circa 70Kb per poi ricominciare ad apparire verso i circa 38Mb di questa pendrive da 128Mb.
Può essere che la MFT faccia due copie di se stessa?
CONTRIBUTO DI BRON 20/10/2009:
Si effettivamente esistono DUE copie di un parte della MFT
vedi : http://www.easeus.com/resource/ntfs-disk-structure.htm
Anche se non propriamente documentate da MS esiste molto reverse-eng sulle strutture.
CONTRIBUTO DI Evgueni Tchijevski 20/10/2009
*MFT Optimization for NTFS Volumes*
When a volume is formatted with NTFS, a Master File Table (MFT) and other special file system metadata files are created. The MFT is an important data structure for NTFS, consisting of many 1K MFT entries that define all items in the file system. All information about a file—including its size, time and date stamps, permissions, and data content—is stored within or described by MFT entries.
In Windows 2000 and earlier versions of Windows NT, the MFT was typically placed at the start of the disk space available to the file system. In Windows XP, the NTFS format utilities place the MFT 3 GB further into the disk space, which has been found to improve system performance by 5 to 10 percent.
Quindi a questo punto non mi stupisco più di trovare entry mft in mezzo al disco.
Dopo una formattazione semplicemente viene ricreato il file $MFT (e tutti gli altri file di sistema) subito dopo il boot secotor che punta ad un'area (MFT table) "a caso" nel disco.
A metà disco invece viene creato il file $MFTMirr, che contiene 4 (o 16) entry per il ripristino (nel caso il file $MFT venga danneggiato) del file $MFT.
Il file $MFT contiente una entry di se stesso proprio per essere utilizzato nell'MFTMirr (che è la copia di $MFT) in caso di fault.
----------------------------------------------
Nanni Bassetti

Finalmente siamo riusciti a generare la Linux Live Distro per Computer Forensics CAINE 1.0.
Abbiamo applicato delle patch utili e migliorative, grazie al contributo dell'amico Maxim Suhanov.
La distro si è arricchita di parecchi tools ed aggiornamenti, improntata sempre alla massima usabilità ed al reporting.
Che dire di più...andate sul sito ed ENJOY IT!
http://www.caine-live.net
|

 (p)Link
(p)Link Storico
Storico Stampa
Stampa






 Feed RSS 0.91
Feed RSS 0.91 Feed Atom 0.3
Feed Atom 0.3