Di seguito gli interventi pubblicati in questa sezione, in ordine cronologico.
Ieri 27/02/2010 ho tenuto il seminario sulla computer forensics a Cosenza presso l'ordine degli ingegneri.
Appena arrivato mi son trovato di fronte l'aula stracolma erano almeno 100 persone di tutte le età pronte a sciropparsi 6 lunghe ore dedicate a questa disciplina.
Sono stato presentato in maniera straordinaria, facendomi sentire come una rock star, ho scoperto che tanti mi seguivano da tempo, sia sul blog sia sulla mailing list di CFI, qualcuno dai tempi del mio corso di ASP e molti a causa della distrbuzione CAINE.
Dopo circa un'oretta dall'inizio una giornalista del "Quotidiano della Calabria" mi ha "sequestrato" per potermi intervistare privatamente, l'evento è andato liscio, dinamico, senza alcun sbadiglio, anzi con tante domande ed hanno tirato fino alla fine!
Ho parlato diffusamente delle best practices, la hash collision, gli aneddoti legati allo svolgimento delle operazioni, le CTP e le CTU, e di CAINE, ringraziando sempre Giancarlo Giustini che iniziò il progetto ed esaltando l'Open Source che peremette anche i passaggi di mano e/o le modifiche ai software (come è successo con AIR ), ho parlato delle collaborazioni proficue con tutti gli amici di sempre e quelli nuovi (da Denis a Maxim, ecc.), insomma una carrellata di argomenti tecnici e umani che ha generato vari spunti di riflessione.
Non mi rendevo conto di quanta gente ci/mi segue, di quanti sono grati di tutto il lavoro di divulgazione gratuita, dei prodotti software realizzati, della disponibilità sempre mostrata...un evento come quello di ieri mi ha fatto capire, che dal 2005 ad oggi le cose sono molto cambiate e che la Rete è un grande mezzo, è un sistema che permette di esprimerti e farti valutare, senza necessariamente aver lavorato per le mega aziende, aver conseguito 100 certificazioni costose, aver frequentato nomi noti o aver vissuto in città importanti...quindi, ancora una volta, GRAZIE A TUTTI per il sostegno e la stima. 
Un ringraziamento particolare all'Ing. Emilio Malizia ed all'Ing. Giuseppe Spina ;)
"A new version of AIR has been released. The primary change is that it now supports the dc3dd imager and doing 2 hashing algorithms. Thanks to Dr. Nanni Bassetti for his modifications and feedback that made this release possible. As always, feedback and comments appreciated."
These are the comments of Steve Gibson on SourceForge.net for the launch of the new release of
AIR (Automated Image and Restore).
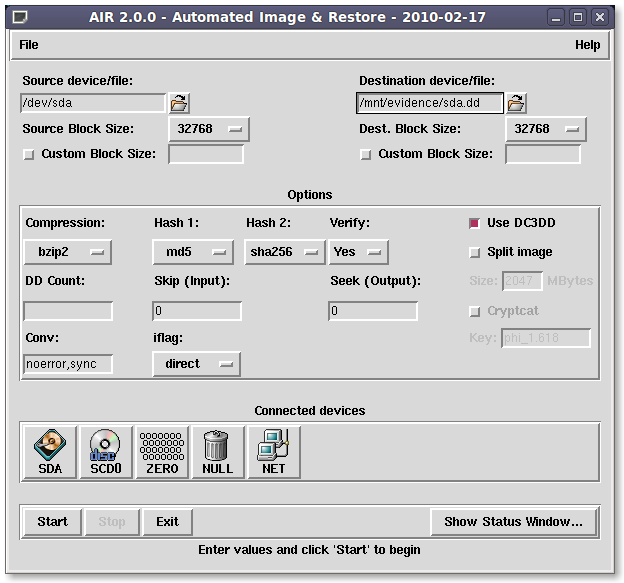
I remember when I used for the first time this precious and useful GUI for the DD and DCFLDD, it was the 2005...me and thousands of people have loved it...and in the 2010 I am in the development team, because I just modified AIR changing DCFLDD with DC3DD, double hashing and iflag setting.
I was very happy that Steve has appreciated my starting changes and then he worked to tune and fix the final release of AIR 2.0.0
Special thanks to the Beta Testers:
Stefano Menozzi (very deep testing)
and
Raffaele Colaianni
AIR WEBSITE: http://air-imager.sourceforge.net/
CAINE & DEFT a confronto su rivista Linux+
E' scritto in Spagnolo, però si capisce...un'approfondita disamina delle due uniche distro forensics gratis ed aggiornate rimaste al mondo:
LINUX+
Buona lettura
AIR 2.0.0 rilasciato:
http://www.nannibassetti.com/dblog/articolo.asp?articolo=99
Ciao a tutti,
ho modificato il famoso AIR (Automated Image and Restore) di Steve Gibson, per farlo girare non più con dcfldd ma con DC3DD, doppio hash, iflag=direct e qualche altra cosina...
Ho l'installer che mi ha inviato Gibson (entusiasta delle mie modifiche), tutto sembra funzionare, però siamo in una fase di testing prima di lanciarlo online...
Chi vuole, può testarlo (inviatemi una mail con nome e cognome) e farmi un feedback su eventuali cose che non vanno.
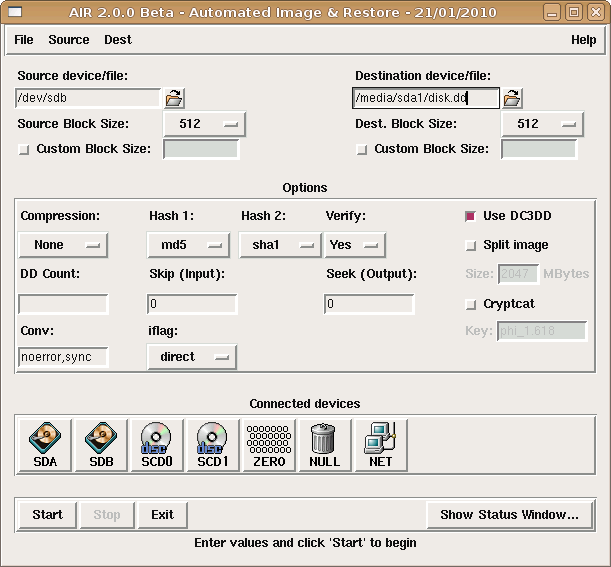
Nel README ci sono le istruzioni, per chi non ha mai installato AIR.
Contattatemi per ricevere l'installer (LINUX ONLY)
AIR 2.0.0 rilasciato:
http://www.nannibassetti.com/dblog/articolo.asp?articolo=99
Grazie PS: ricordatevi di installare DC3DD sui vostri sistemi!
Se si deve acquisire un hard disk in maniera forense, ossia con tutti i crismi necessari al fine di garantire che la copia sia identica all'originale, a tutti quelli che operano nel settore viene subito in mente l'uso di DD, DCFLDD o DC3DD (nel mondo Open Source GNU/Linux), con le classice opzioni e parametri.
Gli approcci sono due:
1) Ottimistico (consideriamo il disco sano e tutti i settori sani)
2) Pessimistico (consideriamo che il disco abbia qualche settore danneggiato)
Nel caso in cui l'approccio ottimistico sia sconfessato, perchè durante l'acquisizione ci si ritrova con degli errori di lettura, allora si tenderà a porsi nell'ottica pessimistica, a volte anche ricominciando tutto d'accapo.
Esaminiamo gli scenari:
dd if=/dev/sdb of=/media/sdc1/disco.dd conv=noerror,sync bs=32K
Il suscritto comando leggerà blocchi da 32Kb dal disco /dev/sdb e scriverà sul disco destinazione /media/sdc1 (montato in scrittura) il file disco.dd, l'opzione conv=noerror,sync serve a due cose:... Continua a leggere...
dd if=/dev/auguri of=/home/buon2010.year conv=noerror count=365 bs=1
mount -t newyear -o rw /dev/luckyman /home/mylife
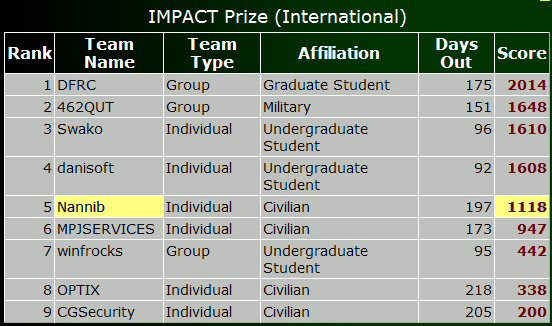
Devo dire che per l'impegno che ci ho messo, davvero poco e frettoloso, sono VERAMENTE CONTENTO ED ORGOGLIOSO di essermi classificato al 5 (Quinto posto) alla DC3 Challenge (la sfida del Dipartimento della Difesa USA sui cybercrimes) nella categoria IMPACT (cittadini extra USA) e 22-esimo nella classifica generale sui 44 finalisti.
http://www.dc3.mil/2009_challenge/stats.php#IMPACT
Il seminario "SCENA DEL CRIMINE: INDAGINI, PROFILING, COMPUTER FORENSICS" tenutosi oggi (28/11/2009), è stato veramente un successone...
Oltre 100 persone (avvocati, magistrati, forze dell'ordine, investigatori privati, consulenti e semplici appassionati), hanno gremito la sala dell'Hotel S. Domenico, per ascoltare in nostri interventi.
Un pubblico veramente attivo e simpatico!
Per me è stato un onore conoscere il giudice Pietro Errede ed il Dott. Luciano Garofano (ex comandante dei R.I.S. di Parma), col quale ci siamo lasciati in ottimi rapporti e progetti.
Walter Paolicelli è stato veramente in gamba ad organizzare tutto e tutto è andato splendidamente, dall'accoglienza in albergo alla cena e pranzo.
Con l'introduzione dell'Avv. Emilio Nicola Buccico e la moderazione del giudice Errede gli argomenti trattati sono stati:
Lo stato dell'arte delle investigazioni e dei consultenti tecnici/periti:
Garofano: "Nelle indagini scientifiche siamo in ritardo"
Mi sono trovato in perfetta sintonia con tutto ciò che ha detto Garofano, c'è un gap pazzesco tra i giudici/avvocati/PM e i tecnici, questo si riflette anche sulle scelte dei periti, che devono operare sui casi in oggetto d'indagine, per non parlare del linguaggio della scienza ancora estraneo a moltissimi.
Poi è stata la volta dell'Avv. Walter Paolicelli che ha parlato del criminal profiling, puntando l'attenzione sul metodo induttivo e sul software Key Crime. Io e Walter ci siamo confrontati sui metodi deduttivo Vs. induttivo, poichè nel campo della digital forensics, personalmente, credo sia più valido il metodo deduttivo.
Il mio intervento è stato su una panoramica sulla digital forensics, il problema della scelta del tecnico e sul come si misurano le competenze, la mancanza di un protocollo rigido e di regole ben definite e poi un breve e veloce escursus sulle best practices e CAINE.
Ha chiuso i lavori l'Avv. Rocco G. Massa, con una overview sulle truffe online, antiche d'origine ma attuate coi mezzi moderni. Molto simaptico è stato l'ascolto di una telefonata tra un truffatore ed un truffato, dove il truffatore sfotteva apertamente il truffato, che rischiava un infarto dalla rabbia!
Nota personale: sono stato molto contento di conoscere tanta gente che segue questo BLOG e la mailing list di CFI. Ci sono state tante proposte di replicare eventi come questo in altre parti d'Italia, con Università e voglia di fare ed andare avanti! Bene...non mi aspettavo che quelle 4 cose che ho prodotto per la computer forensics avessero tanto seguito ed affetto...mi fa molto piacere...GRAZIE A TUTTI! 

Finalmente siamo riusciti a generare la Linux Live Distro per Computer Forensics CAINE 1.0.
Abbiamo applicato delle patch utili e migliorative, grazie al contributo dell'amico Maxim Suhanov.
La distro si è arricchita di parecchi tools ed aggiornamenti, improntata sempre alla massima usabilità ed al reporting.
Che dire di più...andate sul sito ed ENJOY IT!
http://www.caine-live.net
Se si formatta un disco o una pendrive usb, per esempio NTFS, sia con formattazione lenta sia con quella veloce, viene ricreata la MFT (Master File Table), giusto?
I file non vengono cancellati, spariscono alla vista, solo perchè non v'è più un indice, una MFT, che dice al file system dove sono e come si chiamano, ergo usiamo il carving ,(tecnica che non tiene conto del file system), per recuperarli...peccato che si perdono i nomi ed i metadati (data ed ora,e cc.)...giusto?
Non c'è più modo per riavere i nomi dei file, perchè non c'è più MFT che li conserva, essa è stata sovrascritta dalla nuova MFT e tutte le MFT si allocano all'inizio del disco.
Ma come fa RECUVA o R-Studio a recuperare i nomi dei file, ora e date???
L'ho provato su una chiavetta formattata 2 volte, una veloce ed una lenta e poi anche formattando da Linux e comunque riesco a ritrovare alcuni file con il loro nome:
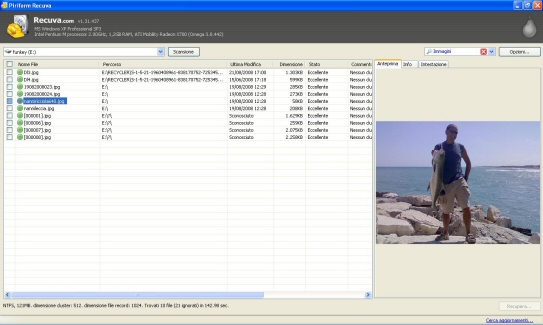
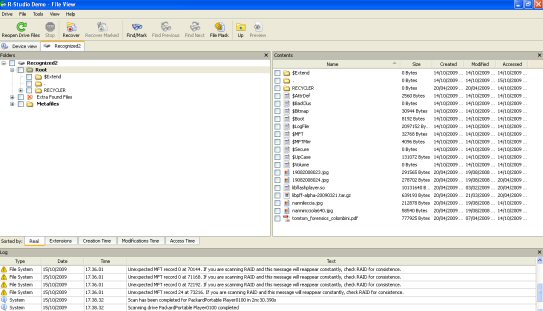
Ho provato con R-Studio ed anche lui ci riesce...solo che ho notato che recupera alcuni metafile della MFT tipo $MFTMirr, $MFTReconstructed, $AttrDef, $Bitmap, $Upcase, $MFT, $Logfile, $Boot che non sono a "0".
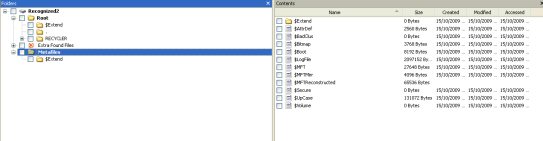
Quindi la spiegazione è che in qualche maniera questi metafile non sono stati sovrascritti con quelli nuovi del nuovo filesystem NTFS quando si formatta...però è strano!
Allora ho voluto provare a "scavare", per capire meglio ed ecco cosa ho ricavato:
strings -a -t d -e l /dev/sdb (ricavo le stringhe contenute nel dispositivo)
...
...
42281714 Dl3.jpg
42282738 Dl4.jpg
42282858 15062008013.jpg
42283762 190820~2.JPGjpg0
42283882 19082008023.jpg
42284786 190820~3.JPGjpg0
42284906 19082008024.jpg
42285810 NANNIR~1.JPGa640
42285930 nanniricciola640.jpg
42286834 NANNIL~1.JPGjpg0
42286954 nannileccia.jpg
...
etc.
Guardo con l'editor esadecimale l'offset in byte 42286954 corrispondente a quello riferito alla stringa: nannileccia.jpg
xxd -s 42286954 -l 512 /dev/sdb
2853f6a: 6e00 6100 6e00 6e00 6900 6c00 6500 6300 n.a.n.n.i.l.e.c.
2853f7a: 6300 6900 6100 2e00 6a00 7000 6700 8000 c.i.a...j.p.g...
2853f8a: 0000 4800 0000 0100 0000 0000 0400 0000 ..H.............
2853f9a: 0000 0000 0000 9f01 0000 0000 0000 4000 ..............@.
2853faa: 0000 0000 0000 0040 0300 0000 0000 8e3f .......@.......?
2853fba: 0300 0000 0000 8e3f 0300 0000 0000 22a0 .......?......".
2853fca: 0165 2800 0100 ffff ffff 8279 4711 0000 ..........e(........yG...
2853fda: 0000 0000 0000 0000 0000 0000 0000 0000 ................
2853fea: 0000 0000 0000 0000 0000 0000 0000 0000 ................
2853ffa: 0000 0000 0b00 0000 0000 0000 0000 0000 ................
285400a: 0000 0000 0000 0000 0000 0000 0000 0000................
Provo a cerca se corrisponde ad un i-node (prova idiota lo so! ma visto che ci siamo )
(42286954 - 0)/512 = 82591 (dato che la partizione inizia dal settore 0 ed il cluster size è di 512 bytes)
ifind -f ntfs -o 0 -d 82591 /dev/sdb
Inode not found
Quindi i nomi file ci sono sulla pendrive, ma non sono contenuti in metafile allocati (giustamente dico io), ma i programmi come Recuva, Get Data Back o R-Studio riescono a riassociare questi nomi file buttati nello spazio del disco formattato con i file presenti e quindi ricostruire l'associazione file - metadato.
Come facciano...bho?
Con Autopsy chiaramente non risultano file cancellati e con una ricerca per DATA UNIT, inserendo il valore 82591, si ottiene la visualizzazione grezza di quel cluster, contenente la stringa "nannileccia.jpg".
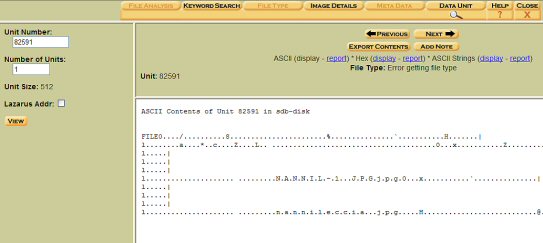
Bhè spero sia argomento interessante ;)
Attendo Vs. suggerimenti
18/10/2009 CONTRIBUTO DI Evgueni Tchijevski
Prova:
-formattato la chiavetta con ntfs :mft entry 1024 byte e cluster da 1024 byte
-aggiunto alcune foto sulla chiavetta
-formattato di nuovo la chiavetta in ntfs
- aggiungo nel file conf di foremost la seguente riga
mft y 1024 FILE0
(in effetti sarebbe stato più corretto aggiungere anche FILE*)
1024 perchè mi serve tutta l'entry mft e la sua dimensione come detto è 1024
faccio il carving sulla chiavetta.
ottengo un sacco di entry mft ed alcune immagini. per brevità riporto quelli che sono considerati nel caso specifico.
(dal file audit.txt)
80: 01302442.mft 1024 B 666850304
.....
116: 01854266.jpg 469 KB 949384192
.....
apro l'entry mft con xxd
soundwave@mrblack:~/lavoro/forense/foremost/foremost-1.5.6/output/mft$ xxd 01302442.mft
0000000: 4649 4c45 3000 0300 7283 4000 0000 0000 FILE0...r.@.....
0000010: 0100 0100 3800 0100 5801 0000 0004 0000 ....8...X.......
0000020: 0000 0000 0000 0000 0300 0000 4000 0000 ............@...
0000030: 0200 0000 0000 0000 1000 0000 6000 0000 ............`...
0000040: 0000 0000 0000 0000 4800 0000 1800 0000 ........H.......
0000050: 40fb dd12 9450 ca01 d0cc 1679 4544 ca01 @....P.....yED..
0000060: 40f4 f312 9450 ca01 40fb dd12 9450 ca01 @....P..@....P..
0000070: 2000 0000 0000 0000 0000 0000 0000 0000 ...............
0000080: 0000 0000 0601 0000 0000 0000 0000 0000 ................
0000090: 0000 0000 0000 0000 3000 0000 7000 0000 ........0...p...
00000a0: 0000 0000 0000 0200 5800 0000 1800 0100 ........X.......
00000b0: 2300 0000 0000 0100 40fb dd12 9450 ca01 #.......@....P..
00000c0: 40fb dd12 9450 ca01 40fb dd12 9450 ca01 @....P..@....P..
00000d0: 40fb dd12 9450 ca01 0058 0700 0000 0000 @....P...X......
00000e0: 0000 0000 0000 0000 2000 0000 0000 0000 ........ .......
00000f0: 0b03 5900 6f00 6b00 6f00 6100 6d00 6900 ..Y.o.k.o.a.m.i.
0000100: 2e00 6a00 7000 6700 8000 0000 4800 0000 ..j.p.g.....H...
0000110: 0100 0000 0000 0100 0000 0000 0000 0000 ................
0000120: d501 0000 0000 0000 4000 0000 0000 0000 ........@.......
0000130: 0058 0700 0000 0000 f457 0700 0000 0000 .X.......W......
0000140: f457 0700 0000 0000 32d6 019d 250e 0000 .W......2...%...
0000150: ffff ffff 8279 4711 0000 0000 0000 0000 .....yG.........
0000160: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000170: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000180: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000190: 0000 0000 0000 0000 0000 0000 0000 0000 ................
ora facendo parsing della entry si ottengono le seguenti info:
strandard information attribute (è riferito alla entry mft)
file creation ( 40fb dd12 9450 ca01) lun, 19 ottobre 2009 08.13.43 UTC
file alteration ( d0cc 1679 4544 ca01) sab, 03 ottobre 2009 16.20.50 UTC
mft alteration ( 40fb dd12 9450 ca01) lun, 19 ottobre 2009 08.13.43 UTC
file read ( 40fb dd12 9450 ca01) lun, 19 ottobre 2009 08.13.43 UTC
file attribute:
file creation lun, 19 ottobre 2009 08.13.43 UTC
file alteration lun, 19 ottobre 2009 08.13.43 UTC
file read lun, 19 ottobre 2009 08.13.43 UTC
un po' di info sulle policy del file Security ID, permission etc...
File allocation size: 0058 0700 ->481280 byte
Filename- >Yokoami.jpg
L'attribute $Data non è residente all'interno dell'$MFT
quindi i dati sono in cluster puntati dalle info contenute:
cioè: number of cluster d6 01 -> 01d6 -> 470 (verifica- >470* 1024 =481280 byte stessa dimensione degli attributi elencati presedentemente)
offset del primo cluster: 9d250e (0e259d- > 927133*1024= 949384192 -guarda caso l'offset del file 01854266.jpg)
quindi 949384192/512- >1854266 (numero del settore).
Quindi ricapitolando. Si possono ottenere le info da una entry mft non più presente nella tabella MFT.
Ora sta a capire il perchè queste info stanno in giro sul disco.
Da quello che ho capito, potrebbe dipendere da allocazioni non residenti di entry mft, da entry presenti all'interno di $LogFile. altre opzioni?
Appena ho un attimo di tempo, cerco di automatizzare il parsing con uno script (se qualcuno ha voglia e tempo per aiutarmi, benvenga :)
my 2cents :)
Evgueni
------------------------------------
CONTRIBUTO DI NANNI BASSETTI 19/10/2009:
Se faccio una ricerca simile:
strings -t d /dev/sdb | grep -i file0
....
....
72192 FILE0
73216 FILE0
74240 FILE0
75264 FILE0
40154592 FILE0
40155152 FILE0
40158688 FILE0
40159248 FILE0
40162784 FILE0
...
...
(i puntini stanno per eccetera eccetera)
Insomma sembra esserci un "buco" tra i circa 70Kb per poi ricominciare ad apparire verso i circa 38Mb di questa pendrive da 128Mb.
Può essere che la MFT faccia due copie di se stessa?
CONTRIBUTO DI BRON 20/10/2009:
Si effettivamente esistono DUE copie di un parte della MFT
vedi : http://www.easeus.com/resource/ntfs-disk-structure.htm
Anche se non propriamente documentate da MS esiste molto reverse-eng sulle strutture.
CONTRIBUTO DI Evgueni Tchijevski 20/10/2009
*MFT Optimization for NTFS Volumes*
When a volume is formatted with NTFS, a Master File Table (MFT) and other special file system metadata files are created. The MFT is an important data structure for NTFS, consisting of many 1K MFT entries that define all items in the file system. All information about a file—including its size, time and date stamps, permissions, and data content—is stored within or described by MFT entries.
In Windows 2000 and earlier versions of Windows NT, the MFT was typically placed at the start of the disk space available to the file system. In Windows XP, the NTFS format utilities place the MFT 3 GB further into the disk space, which has been found to improve system performance by 5 to 10 percent.
Quindi a questo punto non mi stupisco più di trovare entry mft in mezzo al disco.
Dopo una formattazione semplicemente viene ricreato il file $MFT (e tutti gli altri file di sistema) subito dopo il boot secotor che punta ad un'area (MFT table) "a caso" nel disco.
A metà disco invece viene creato il file $MFTMirr, che contiene 4 (o 16) entry per il ripristino (nel caso il file $MFT venga danneggiato) del file $MFT.
Il file $MFT contiente una entry di se stesso proprio per essere utilizzato nell'MFTMirr (che è la copia di $MFT) in caso di fault.
----------------------------------------------
Nanni Bassetti
|

 (p)Link
(p)Link Storico
Storico Stampa
Stampa





 Feed RSS 0.91
Feed RSS 0.91 Feed Atom 0.3
Feed Atom 0.3